library(AER) # pacote com dados do livro
library(tidyverse) # manipulação e visualização de dados
library(modelsummary) # tabelas de comparação de modelos
library(gt) # tabelas com qualidade de publicação
library(gtExtras) # temas adicionais para gt
library(sandwich) # erros-padrão robustos
library(lmtest) # testes com erros-padrão robustos
library(skimr) # estatísticas descritivas
library(marginaleffects) # pacote para calculo de efeitos marginais e previsõesAula Prática - Variável Dependente Limitada
1 Introdução
Nesta aula prática, replicaremos os principais resultados do Capítulo 11 de Stock e Watson (2020), que trata de modelos de regressão com variável dependente limitada A aplicação empírica central explora a seguinte pergunta: existe discriminação racial no mercado de crédito imobiliário nos Estados Unidos?
Para responder a essa pergunta, utilizamos os dados do HMDA (Home Mortgage Disclosure Act), coletados pelo Federal Reserve de Boston. A base contém 2.380 observações de solicitações individuais de hipotecas para residências unifamiliares feitas em 1990 na Grande Boston. A variável dependente é deny, uma variável binária igual a 1 se a solicitação foi negada e 0 caso contrário.
O conjunto de dados possui um conjunto de informações financeiras e características dos solicitantes, o que nos permite verificar se, após controlar por esses fatores, ainda existe evidência de discriminação racial.
2 Pacotes e Dados
Os pacotes utilizados nesta aula são:
A base de dados HMDA está disponível diretamente no pacote AER. Após carregá-la, transformamos as variáveis categóricas em variáveis numéricas binárias e criamos indicadores para as categorias da razão empréstimo/valor. Para ver a definição de cada variável, consulte a página de documentação do pacote no R.1 2
1 No pacote AER, as variáveis deny, afam, phist, insurance, selfemp, single e hschool são fatores com níveis "no" e "yes". As variáveis chist e mhist são fatores ordenados. A conversão abaixo as transforma em variáveis numéricas 0/1 para uso nos modelos de regressão.
2 Em um LPM, \(\text{Var}(u_i \mid X_i) = \Pr(Y_i = 1 \mid X_i)[1 - \Pr(Y_i = 1 \mid X_i)]\), que varia com \(X_i\) por construção. Portanto, erros-padrão robustos são sempre necessários no LPM.
# Carregar os dados
data("HMDA", package = "AER")
# Preparação dos dados
hmda <- HMDA |>
mutate(
deny = if_else(deny == "yes", 1, 0),
afam = if_else(afam == "yes", 1, 0),
phist = if_else(phist == "yes", 1, 0),
insurance = if_else(insurance == "yes", 1, 0),
selfemp = if_else(selfemp == "yes", 1, 0),
single = if_else(single == "yes", 1, 0),
hschool = if_else(hschool == "yes", 1, 0),
chist = as.numeric(as.character(chist)),
mhist = as.numeric(as.character(mhist)),
# Indicadores para razão empréstimo/valor (referência: lvrat < 0,80)
lvrat_med = if_else(lvrat >= 0.80 & lvrat <= 0.95, 1, 0),
lvrat_high = if_else(lvrat > 0.95, 1, 0),
# criando variáveis de crédito de controle adicionais
chist_3 = if_else(chist == 3,1,0),
chist_4 = if_else(chist == 4,1,0),
chist_5 = if_else(chist == 5,1,0),
chist_6 = if_else(chist == 6,1,0),
mhist_3 = if_else(mhist == 3,1,0),
mhist_4 = if_else(mhist == 4,1,0)
)
glimpse(hmda)Rows: 2,380
Columns: 22
$ deny <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,…
$ pirat <dbl> 0.221, 0.265, 0.372, 0.320, 0.360, 0.240, 0.350, 0.280, 0.3…
$ hirat <dbl> 0.221, 0.265, 0.248, 0.250, 0.350, 0.170, 0.290, 0.220, 0.2…
$ lvrat <dbl> 0.8000000, 0.9218750, 0.9203980, 0.8604651, 0.6000000, 0.51…
$ chist <dbl> 5, 2, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 1, 1, 1, 2, 1, 2, 2, 2,…
$ mhist <dbl> 2, 2, 2, 2, 1, 1, 2, 2, 2, 1, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2,…
$ phist <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ unemp <dbl> 3.9, 3.2, 3.2, 4.3, 3.2, 3.9, 3.9, 1.8, 3.1, 3.9, 3.1, 4.3,…
$ selfemp <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ insurance <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,…
$ condomin <fct> no, no, no, no, no, no, yes, no, no, no, yes, no, no, no, n…
$ afam <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ single <dbl> 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,…
$ hschool <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ lvrat_med <dbl> 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1,…
$ lvrat_high <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ chist_3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ chist_4 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ chist_5 <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ chist_6 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ mhist_3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ mhist_4 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…2.1 Dicionário de variáveis
A Tabela 1 apresenta as principais variáveis da base e suas médias amostrais, conforme reportado na Tabela 11.1 do livro.
# 1: Criar um data.frame com o nome das variáveis e definições.
vars_def <- tribble(
~skim_variable, ~Definição,
"deny", "1 se a hipoteca foi negada; 0 caso contrário",
"pirat", "Razão pagamentos mensais totais / renda mensal total",
"hirat", "Razão despesas habitacionais mensais / renda mensal total",
"lvrat", "Razão valor do empréstimo / valor avaliado do imóvel",
"chist", "Score de crédito ao consumidor (1–6; valores maiores = histórico pior)",
"mhist", "Score de crédito hipotecário (1–4; valores maiores = histórico pior)",
"phist", "1 se há registro público de crédito ruim; 0 caso contrário",
"insurance", "1 se o seguro hipotecário foi negado; 0 caso contrário",
"selfemp", "1 se o solicitante é autônomo; 0 caso contrário",
"single", "1 se o solicitante é solteiro; 0 caso contrário",
"hschool", "1 se o solicitante tem ensino médio completo; 0 caso contrário",
"afam", "1 se o solicitante é negro; 0 caso contrário"
)
medias <- hmda |>
select(deny, pirat, hirat, lvrat, chist, mhist, phist, insurance, selfemp, single, hschool, afam) |>
skim() |>
as_tibble() # essa opção função coloca os resultados em formato data.frame
# select(skim_variable, media = numeric.mean) |> # dentre as estatísticas descritivas, seleciona apenas a média.
#2. Juntar as médias calculadas e a definição das variáveis
medias <- medias |>
left_join(vars_def, by = "skim_variable") |>
rename(Variável = skim_variable) |> #ajusta o nome das variáveis
select(Variável, Definição, `Média Amostral` = numeric.mean) # seleciona apenas o que se quer mostrar na tabela
#3. Prepara uma tabela formato publicação
medias |>
gt() |>
fmt_number(columns = `Média Amostral`, decimals = 3, dec_mark = ",", sep_mark = ".") |>
tab_header(
title = md("**Variáveis da Base HMDA de Boston**"),
subtitle = md("Solicitações de hipotecas — Grande Boston, 1990")
) |>
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_labels()
) |>
tab_source_note(
md("Fonte: Federal Reserve de Boston. Disponível via `AER::HMDA`.")
) |>
opt_stylize(style = 6, color = "gray")| Variáveis da Base HMDA de Boston | ||
|---|---|---|
| Solicitações de hipotecas — Grande Boston, 1990 | ||
| Variável | Definição | Média Amostral |
| deny | 1 se a hipoteca foi negada; 0 caso contrário | 0,120 |
| pirat | Razão pagamentos mensais totais / renda mensal total | 0,331 |
| hirat | Razão despesas habitacionais mensais / renda mensal total | 0,255 |
| lvrat | Razão valor do empréstimo / valor avaliado do imóvel | 0,738 |
| chist | Score de crédito ao consumidor (1–6; valores maiores = histórico pior) | 2,116 |
| mhist | Score de crédito hipotecário (1–4; valores maiores = histórico pior) | 1,721 |
| phist | 1 se há registro público de crédito ruim; 0 caso contrário | 0,074 |
| insurance | 1 se o seguro hipotecário foi negado; 0 caso contrário | 0,020 |
| selfemp | 1 se o solicitante é autônomo; 0 caso contrário | 0,116 |
| single | 1 se o solicitante é solteiro; 0 caso contrário | 0,393 |
| hschool | 1 se o solicitante tem ensino médio completo; 0 caso contrário | 0,984 |
| afam | 1 se o solicitante é negro; 0 caso contrário | 0,142 |
Fonte: Federal Reserve de Boston. Disponível via AER::HMDA. |
||
3 Análise Exploratória
3.1 Taxa de negação por raça
A Tabela 2 mostra a taxa de negação de hipotecas para solicitantes negros e brancos. A diferença bruta é substancial e motiva a análise de regressão que se segue.
#1. Calcula as estatísticas por raça
stats_raca <- hmda |>
mutate(Raça = if_else(afam == 1, "Negro", "Branco")) |>
group_by(Raça) |>
summarise(
N = n(),
`Pedidos Negados` = sum(deny),
`Taxa de Negação` = mean(deny)
)
#2. Calcula as estatísticas sem distinção de raça
stats_totais <- bind_rows(
hmda |>
summarise(
Raça = "Total",
N = n(),
`Pedidos Negados` = sum(deny),
`Taxa de Negação` = mean(deny)
)
)
#3. Junta os dois objetos acima em um objeto único e prepara tabela de publicação
stats <- stats_raca |>
bind_rows(stats_totais)
stats |>
gt() |>
tab_header(
title = md("**Taxa de Negação de Hipotecas por Raça**"),
subtitle = "Dados HMDA — Grande Boston, 1990"
) |>
fmt_number(columns = `Taxa de Negação`, decimals = 3) |>
fmt_integer(columns = c(N, `Pedidos Negados`)) |>
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_labels()
) |>
tab_style(
style = cell_fill(color = "#EBF5FB"),
locations = cells_body(rows = Raça == "Total")
) |>
tab_source_note("n = 2.380 observações.") |>
opt_stylize(style = 6, color = "gray")| Taxa de Negação de Hipotecas por Raça | |||
|---|---|---|---|
| Dados HMDA — Grande Boston, 1990 | |||
| Raça | N | Pedidos Negados | Taxa de Negação |
| Branco | 2,041 | 189 | 0.093 |
| Negro | 339 | 96 | 0.283 |
| Total | 2,380 | 285 | 0.120 |
| n = 2.380 observações. | |||
Solicitantes negros têm uma taxa de negação de aproximadamente 28%, contra cerca de 9% para solicitantes brancos — uma diferença bruta de quase 19 pontos percentuais. No entanto, parte dessa diferença pode refletir diferenças nas condições financeiras dos solicitantes, e não discriminação racial. Os modelos de regressão abaixo permitem controlar por essas características.
3.2 Distribuição da razão P/I por resultado
A Figura 1 mostra a distribuição da razão pagamentos/renda (pirat) separada por resultado da solicitação. Solicitantes com pedido negado tendem, em média, a ter razão P/I mais alta.
hmda |>
mutate(Resultado = if_else(deny == 1, "Negado", "Aprovado")) |>
ggplot(aes(x = pirat, fill = Resultado)) +
geom_histogram(aes(y = after_stat(density)),
bins = 40, alpha = 0.7, position = "identity") +
scale_fill_manual(values = c("Aprovado" = "#1565C0", "Negado" = "#C62828")) +
labs(
x = "Razão pagamentos / renda (pirat)",
y = "Densidade",
fill = "Resultado",
title = "Distribuição da Razão P/I por Resultado da Solicitação",
subtitle = "Dados HMDA — Grande Boston, 1990"
) +
theme_minimal(base_size = 13) +
theme(legend.position = "top")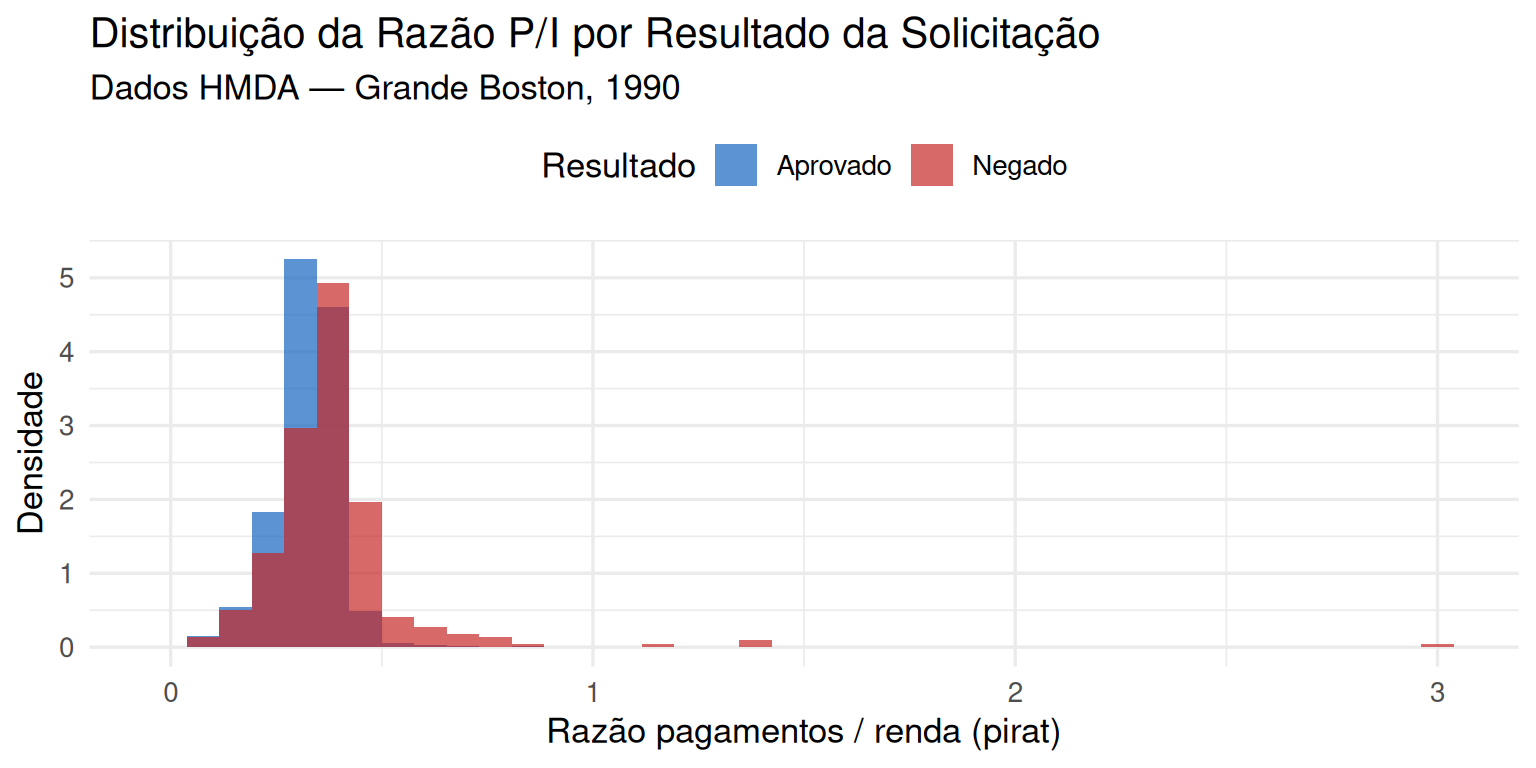
4 Modelo de Probabilidade Linear
4.1 Formulação
O Modelo de Probabilidade Linear (LPM) aplica o estimador de MQO diretamente à variável binária deny. Como \(E(Y \mid X) = \Pr(Y = 1 \mid X)\) quando \(Y\) é binária, o valor previsto pelo LPM é interpretado como a probabilidade condicional de negação:
\[\Pr(\text{deny} = 1 \mid X) = \beta_0 + \beta_1 \cdot \text{pirat}\]
Utilizamos erros-padrão robustos à heterocedasticidade (HC1) por meio do pacote sandwich, pois quando a variável dependente é binária, a heterocedasticidade é inerente ao modelo.3
3 Em um LPM, \(\text{Var}(u_i \mid X_i) = \Pr(Y_i = 1 \mid X_i)[1 - \Pr(Y_i = 1 \mid X_i)]\), que varia com \(X_i\) por construção. Portanto, erros-padrão robustos são sempre necessários no LPM.
4.2 Regressão simples: deny ~ pirat
lpm_simples <- lm(deny ~ pirat, data = hmda)
coeftest(lpm_simples, vcov = vcovHC(lpm_simples, type = "HC1"))
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.079910 0.031967 -2.4998 0.01249 *
pirat 0.603535 0.098483 6.1283 1.036e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interpretação: O coeficiente de pirat é positivo e estatisticamente significativo. Um aumento de 0,1 unidade na razão P/I (equivalente a 100 pontos percentuais) está associado a um aumento de aproximadamente \(0,604 \times 0,1 = 0,06\) na probabilidade de negação, ou seja, 6 pontos percentuais.
Calculando as probabilidades previstas para P/I = 0,3 e P/I = 0,4:
predict(lpm_simples, newdata = tibble(pirat = c(0.3, 0.4))) 1 2
0.1011508 0.1615043 O efeito de aumentar a razão P/I de 0,3 para 0,4 é elevar a probabilidade de negação em cerca de 6 pontos percentuais.
4.3 Incluindo raça como regressor: deny ~ pirat + afam
lpm_raca <- lm(deny ~ pirat + afam, data = hmda)
coeftest(lpm_raca, vcov = vcovHC(lpm_raca, type = "HC1"))
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.090514 0.028600 -3.1649 0.001571 **
pirat 0.559195 0.088666 6.3067 3.387e-10 ***
afam 0.177428 0.024946 7.1124 1.502e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interpretação: O coeficiente de afam é positivo e estatisticamente significativo. Controlando pela razão P/I, um solicitante negro tem probabilidade de negação aproximadamente 17,7 pontos percentuais maior do que um solicitante branco com a mesma razão P/I.
Probabilidades previstas para um solicitante com P/I = 0,3, por raça:
tibble(pirat = 0.3, afam = c(1, 0)) |>
mutate(
Raça = if_else(afam == 1, "Negro", "Branco"),
`Prob. prevista (LPM)` = predict(lpm_raca, newdata = pick(pirat, afam))
) |>
select(Raça, `Prob. prevista (LPM)`)# A tibble: 2 × 2
Raça `Prob. prevista (LPM)`
<chr> <dbl>
1 Negro 0.255
2 Branco 0.07724.4 Limitações do LPM
O LPM apresenta duas limitações importantes:
Efeito constante: O modelo impõe que o efeito de
piratsobre a probabilidade de negação é o mesmo para qualquer valor depirat. Isso não é realista: intuitivamente, o efeito deveria ser menor quando a probabilidade já está próxima de 0 ou de 1.Probabilidades fora de [0, 1]: O LPM pode prever probabilidades negativas ou maiores que 1, o que é teoricamente inconsistente.
# Verificar amplitude das probabilidades previstas
range(predict(lpm_raca))[1] -0.0905136 1.5870702Os modelos probit e logit, apresentados a seguir, corrigem essas limitações ao impor que as probabilidades previstas estejam sempre dentro do intervalo [0, 1].
5 Modelo Probit
5.1 Formulação
O modelo probit modela a probabilidade de negação usando a função de distribuição normal padrão acumulada, \(\Phi\):
\[\Pr(\text{deny} = 1 \mid X) = \Phi(\beta_0 + \beta_1 \cdot X_1 + \ldots + \beta_k \cdot X_k)\]
O argumento \(z = \beta_0 + \beta_1 X_1 + \ldots\) é chamado de índice-z. O coeficiente \(\beta_1\) representa a variação no índice-z associada a uma variação unitária em \(X_1\), e não representa diretamente a variação na probabilidade. Para obter os efeitos sobre a probabilidade, precisamos fazer o calculo em etapas.
O probit é estimado por máxima verossimilhança (MV) e os estimadores têm distribuição normal assintótica, permitindo inferência pelo procedimento usual.
5.2 Regressão simples: deny ~ pirat
probit_simples <- glm(deny ~ pirat,
data = hmda,
family = binomial(link = "probit"))
summary(probit_simples)
Call:
glm(formula = deny ~ pirat, family = binomial(link = "probit"),
data = hmda)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.1941 0.1378 -15.927 < 2e-16 ***
pirat 2.9679 0.3858 7.694 1.43e-14 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1744.2 on 2379 degrees of freedom
Residual deviance: 1663.6 on 2378 degrees of freedom
AIC: 1667.6
Number of Fisher Scoring iterations: 6Probabilidades previstas para P/I = 0,3 e P/I = 0,4:
predict(probit_simples,
newdata = tibble(pirat = c(0.3, 0.4)),
type = "response") 1 2
0.09615344 0.15696777 O efeito de aumentar a razão P/I de 0,3 para 0,4 é elevar a probabilidade de negação de aproximadamente 9,7% para 15,9%, ou seja, 6,2 pontos percentuais. Note que neste caso, o resultado obtido é próximo ao resultado do LPM, mas em um modelo em que as probabilidades respeitam o intervalo [0, 1] e com efeito não constante.4
4 Isto acontece porque estamos avaliando o impacto em valores próximos da média de pirate não nos extremos. Se quiser testar, você pode alterar o código e verifique a diferença para pontos no extremo e compare com o previsto pelo LPM.
5.3 Regressão com raça: deny ~ pirat + afam
probit_raca <- glm(deny ~ pirat + afam,
data = hmda,
family = binomial(link = "probit"))
summary(probit_raca)
Call:
glm(formula = deny ~ pirat + afam, family = binomial(link = "probit"),
data = hmda)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.25879 0.13669 -16.525 < 2e-16 ***
pirat 2.74178 0.38047 7.206 5.75e-13 ***
afam 0.70816 0.08335 8.496 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1744.2 on 2379 degrees of freedom
Residual deviance: 1594.3 on 2377 degrees of freedom
AIC: 1600.3
Number of Fisher Scoring iterations: 5Probabilidades previstas para P/I = 0,3, por raça:
predictions(probit_raca,
newdata = datagrid(pirat = 0.3, afam = c(0, 1))) |>
as_tibble() |>
mutate(Raça = if_else(afam == 1, "Negro", "Branco")) |>
select(Raça, `Prob. prevista` = estimate, `IC 95% — inf.` = conf.low, `IC 95% — sup.` = conf.high)# A tibble: 2 × 4
Raça `Prob. prevista` `IC 95% — inf.` `IC 95% — sup.`
<chr> <dbl> <dbl> <dbl>
1 Branco 0.0755 0.0642 0.0882
2 Negro 0.233 0.190 0.282 Para um solicitante com P/I = 0,3, a probabilidade prevista de negação é de cerca de 7,5% para brancos e 23,3% para negros, uma diferença de aproximadamente 15,8 pontos percentuais.
5.4 Visualização das probabilidades previstas
A Figura 2 mostra as probabilidades previstas pelo modelo probit para solicitantes negros e brancos ao longo de diferentes valores da razão P/I, destacando a forma em “S” e o diferencial racial persistente.
predictions(probit_raca,
# nesta parte do código geramos valores para pirat que vão de 0 a 1 a cada 0,1
newdata = datagrid(
pirat = seq(0, 1, by = 0.01),
afam = c(0, 1)
)) |>
as_tibble() |>
mutate(Raça = if_else(afam == 1, "Negro", "Branco")) |>
ggplot(aes(x = pirat, y = estimate, color = Raça, fill = Raça)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = 0.15, color = NA) +
geom_line(linewidth = 1) +
scale_color_manual(values = c("Negro" = "#C62828", "Branco" = "#1565C0")) +
scale_fill_manual(values = c("Negro" = "#C62828", "Branco" = "#1565C0")) +
scale_y_continuous(labels = scales::label_percent()) +
labs(
x = "Razão pagamentos / renda (pirat)",
y = "Probabilidade prevista de negação",
color = "Raça do solicitante",
fill = "Raça do solicitante",
title = "Probabilidades Previstas pelo Modelo Probit",
subtitle = "Hipoteca negada em função da razão P/I e raça"
) +
theme_minimal(base_size = 13) +
theme(legend.position = "top")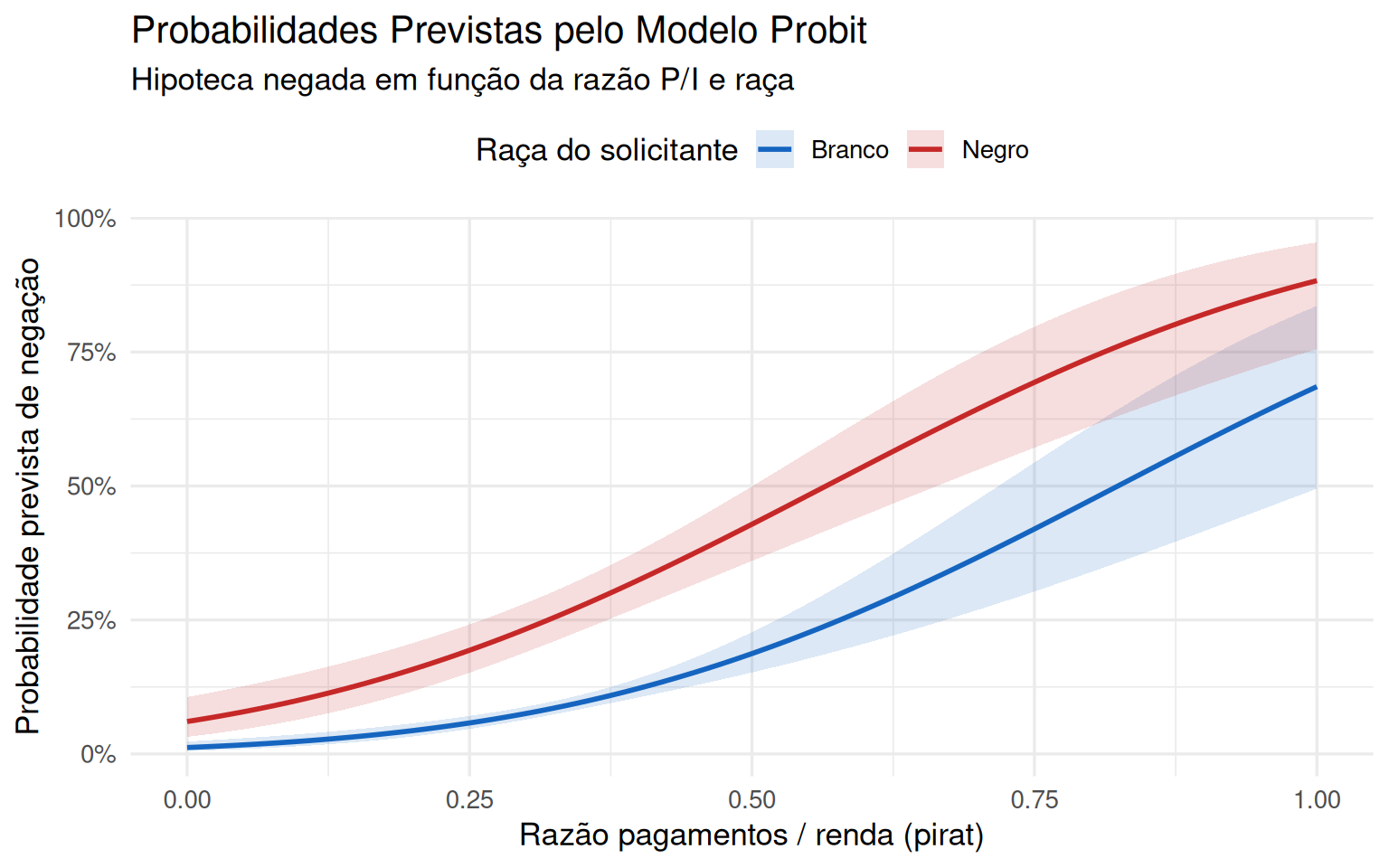
A forma em “S” das curvas ilustra a principal vantagem do probit sobre o LPM: as probabilidades previstas permanecem dentro de [0, 1] para qualquer valor da razão P/I. Além disso, o efeito marginal de pirat não é constante, sendo maior na região central e menor nos extremos, o que faz mais sentido do ponto de vista econômico.
6 Modelo Logit
O modelo logit substitui a função normal acumulada \(\Phi\) pela função de distribuição logística \(F(z) = \frac{1}{1 + e^{-z}}\):
\[\Pr(\text{deny} = 1 \mid X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 \cdot \text{pirat} + \beta_2 \cdot \text{afam})}}\]
As duas funções têm forma semelhante em “S”, e na prática os resultados são muito próximos.
logit_raca <- glm(deny ~ pirat + afam,
data = hmda,
family = binomial(link = "logit"))
summary(logit_raca)
Call:
glm(formula = deny ~ pirat + afam, family = binomial(link = "logit"),
data = hmda)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.1256 0.2684 -15.370 < 2e-16 ***
pirat 5.3704 0.7283 7.374 1.66e-13 ***
afam 1.2728 0.1462 8.706 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1744.2 on 2379 degrees of freedom
Residual deviance: 1591.4 on 2377 degrees of freedom
AIC: 1597.4
Number of Fisher Scoring iterations: 5Probabilidades previstas para P/I = 0,3, por raça:
predictions(logit_raca,
newdata = datagrid(pirat = 0.3, afam = c(0, 1))) |>
as_tibble() |>
mutate(Raça = if_else(afam == 1, "Negro", "Branco")) |>
select(Raça, `Prob. prevista` = estimate, `IC 95% — inf.` = conf.low, `IC 95% — sup.` = conf.high)# A tibble: 2 × 4
Raça `Prob. prevista` `IC 95% — inf.` `IC 95% — sup.`
<chr> <dbl> <dbl> <dbl>
1 Branco 0.0749 0.0639 0.0875
2 Negro 0.224 0.182 0.272 As probabilidades previstas pelo logit (branco ≈ 7,5%, negro ≈ 22,5%) são muito próximas às do probit (branco ≈ 7,5%, negro ≈ 23,3%). Esse resultado ilustra um padrão geral: para fins empíricos, probit e logit produzem probabilidades previstas muito semelhantes, e a escolha entre eles raramente altera as conclusões substantivas.
7 Especificações Completas — Replicando a Tabela 11.2
Estimamos cinco especificações, aproximando a Tabela 11.2 do livro. As especificações vão de um MPL simples até um probit com interações de raça, o que nos permite avaliar a robustez do coeficiente de afam à inclusão de controles adicionais.
# Modelo (1): MPL — variáveis financeiras e características do solicitante
mod1_lpm <- lm(
deny ~ afam + pirat + hirat + lvrat_med + lvrat_high +
chist + mhist + phist + insurance + selfemp,
data = hmda
)
# Modelo (2): Logit — mesmas variáveis
mod2_logit <- glm(
deny ~ afam + pirat + hirat + lvrat_med + lvrat_high +
chist + mhist + phist + insurance + selfemp,
data = hmda,
family = binomial(link = "logit")
)
# Modelo (3): Probit — mesmas variáveis
mod3_probit <- glm(
deny ~ afam + pirat + hirat + lvrat_med + lvrat_high +
chist + mhist + phist + insurance + selfemp,
data = hmda,
family = binomial(link = "probit")
)
# Modelo (4): Probit — adiciona situação pessoal do solicitante
mod4_probit <- glm(
deny ~ afam + pirat + hirat + lvrat_med + lvrat_high +
chist + mhist + phist + insurance + selfemp +
single + hschool + unemp,
data = hmda,
family = binomial(link = "probit")
)
# Modelo (5): Probit — adiciona a variável condominio
mod5_probit <- glm(
deny ~ afam + pirat + hirat + lvrat_med + lvrat_high +
chist + mhist + phist + insurance + selfemp +
single + hschool + condomin + unemp + chist_3 +
chist_4 + chist_5 + chist_6 + mhist_3 + mhist_4,
data = hmda,
family = binomial(link = "probit")
)
# Modelo (6): Probit — adiciona interações de raça com variáveis financeiras (s/ condominio)
mod6_probit <- glm(
deny ~ afam + pirat + hirat + lvrat_med + lvrat_high +
chist + mhist + phist + insurance + selfemp +
single + hschool + unemp +
afam:pirat + afam:hirat,
data = hmda,
family = binomial(link = "probit")
)A Tabela 3 apresenta os resultados das cinco especificações com erros-padrão robustos.
modelos <- list(
"LPM (1)" = mod1_lpm,
"Logit (2)" = mod2_logit,
"Probit (3)" = mod3_probit,
"Probit (4)" = mod4_probit,
"Probit (5)" = mod5_probit,
"Probit (6)" = mod6_probit
)
nomes_coef <- c(
"afam" = "Negro",
"pirat" = "Razão pagamentos/renda",
"hirat" = "Razão despesas habitacionais/renda",
"lvrat_med" = "Razão empr./valor médio (0,80–0,95)",
"lvrat_high" = "Razão empr./valor alto (> 0,95)",
"chist" = "Score crédito ao consumidor",
"mhist" = "Score crédito hipotecário",
"phist" = "Registro público de crédito ruim",
"insurance" = "Seguro hipotecário negado",
"selfemp" = "Autônomo",
"single" = "Solteiro",
"hschool" = "Diploma de ensino médio",
"unemp" = "Taxa de desemprego",
"condominyes" = "Condominios",
"afam:pirat" = "Negro × Razão pagamentos/renda",
"afam:hirat" = "Negro × Razão despesas habitacionais/renda",
"(Intercept)" = "Constante"
)
modelsummary(
modelos,
fmt = 2,
vcov = "HC1",
stars = c("*" = 0.05, "**" = 0.01),
coef_map = nomes_coef,
gof_map = list(
list(raw = "nobs", clean = "Observações", fmt = 0)),
notes = "Erros-padrão robustos (HC1) entre parênteses. * p < 0,05; ** p < 0,01.",
output = "gt"
) |>
tab_header(
title = md("**Tabela 11.2 — Regressões de Negação de Hipoteca**"),
subtitle = md("Variável dependente: *deny* = 1 se a solicitação foi negada; n = 2.380")
) |>
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_labels()
) |>
tab_style(
style = cell_fill(color = "#EBF5FB"),
locations = cells_body(rows = 1)
) |>
opt_stylize(style = 6, color = "gray") |>
tab_options(table.font.size = px(12))| Tabela 11.2 — Regressões de Negação de Hipoteca | ||||||
|---|---|---|---|---|---|---|
| Variável dependente: deny = 1 se a solicitação foi negada; n = 2.380 | ||||||
| LPM (1) | Logit (2) | Probit (3) | Probit (4) | Probit (5) | Probit (6) | |
| Negro | 0.08** | 0.69** | 0.39** | 0.37** | 0.36** | 0.25 |
| (0.02) | (0.18) | (0.10) | (0.10) | (0.10) | (0.48) | |
| Razão pagamentos/renda | 0.45** | 4.76** | 2.44** | 2.46** | 2.62** | 2.57** |
| (0.11) | (1.33) | (0.67) | (0.65) | (0.66) | (0.73) | |
| Razão despesas habitacionais/renda | -0.05 | -0.11 | -0.18 | -0.30 | -0.50 | -0.54 |
| (0.11) | (1.30) | (0.69) | (0.69) | (0.72) | (0.76) | |
| Razão empr./valor médio (0,80–0,95) | 0.03* | 0.46** | 0.21** | 0.22** | 0.22* | 0.22** |
| (0.01) | (0.16) | (0.08) | (0.08) | (0.08) | (0.08) | |
| Razão empr./valor alto (> 0,95) | 0.19** | 1.49** | 0.79** | 0.79** | 0.84** | 0.79** |
| (0.05) | (0.32) | (0.18) | (0.18) | (0.18) | (0.19) | |
| Score crédito ao consumidor | 0.03** | 0.29** | 0.15** | 0.16** | 0.34** | 0.16** |
| (0.00) | (0.04) | (0.02) | (0.02) | (0.11) | (0.02) | |
| Score crédito hipotecário | 0.02 | 0.28* | 0.15* | 0.11 | 0.16 | 0.11 |
| (0.01) | (0.14) | (0.07) | (0.08) | (0.10) | (0.08) | |
| Registro público de crédito ruim | 0.20** | 1.23** | 0.70** | 0.70** | 0.72** | 0.70** |
| (0.03) | (0.20) | (0.11) | (0.12) | (0.12) | (0.11) | |
| Seguro hipotecário negado | 0.70** | 4.55** | 2.56** | 2.59** | 2.59** | 2.59** |
| (0.05) | (0.58) | (0.31) | (0.30) | (0.31) | (0.30) | |
| Autônomo | 0.06** | 0.67** | 0.36** | 0.35** | 0.34** | 0.35** |
| (0.02) | (0.21) | (0.11) | (0.12) | (0.12) | (0.12) | |
| Solteiro | 0.23** | 0.23** | 0.23** | |||
| (0.08) | (0.09) | (0.08) | ||||
| Diploma de ensino médio | -0.61** | -0.60* | -0.62** | |||
| (0.23) | (0.24) | (0.23) | ||||
| Taxa de desemprego | 0.03 | 0.03 | 0.03 | |||
| (0.02) | (0.02) | (0.02) | ||||
| Condominios | -0.05 | |||||
| (0.10) | ||||||
| Negro × Razão pagamentos/renda | -0.58 | |||||
| (1.55) | ||||||
| Negro × Razão despesas habitacionais/renda | 1.23 | |||||
| (1.71) | ||||||
| Constante | -0.18** | -5.71** | -3.04** | -2.57** | -2.90** | -2.54** |
| (0.03) | (0.48) | (0.25) | (0.35) | (0.40) | (0.37) | |
| Observações | 2380 | 2380 | 2380 | 2380 | 2380 | 2380 |
| * p < 0.05, ** p < 0.01 | ||||||
| Erros-padrão robustos (HC1) entre parênteses. * p < 0,05; ** p < 0,01. | ||||||
7.1 Diferença prevista na probabilidade de negação: branco vs. negro
Para comparar as especificações em termos substantivos, calculamos, para cada modelo, a diferença na probabilidade de negação entre um solicitante negro e um branco com todas as demais variáveis iguais à média amostral:
calcular_diferenca <- function(modelo, nome) {
nd <- datagrid(model = modelo, afam = c(0, 1))
preds <- predictions(modelo, newdata = nd)
tibble(
Modelo = nome,
`Diferença (p.p.)` = round((preds$estimate[2] - preds$estimate[1]) * 100, 1)
)
}
bind_rows(
calcular_diferenca(mod1_lpm, "LPM (1)"),
calcular_diferenca(mod2_logit, "Logit (2)"),
calcular_diferenca(mod3_probit, "Probit (3)"),
calcular_diferenca(mod4_probit, "Probit (4)"),
calcular_diferenca(mod5_probit, "Probit (5)")
) |>
gt() |>
tab_header(
title = md("**Diferença Prevista na Probabilidade de Negação**"),
subtitle = md("Negro vs. branco, demais variáveis fixadas na média amostral")
) |>
fmt_number(columns = `Diferença (p.p.)`, decimals = 1, suffix = " p.p.") |>
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_labels()
) |>
tab_source_note("p.p. = pontos percentuais.") |>
opt_stylize(style = 6, color = "gray")| Diferença Prevista na Probabilidade de Negação | |
|---|---|
| Negro vs. branco, demais variáveis fixadas na média amostral | |
| Modelo | Diferença (p.p.) |
| LPM (1) | 8.4 |
| Logit (2) | 4.0 |
| Probit (3) | 5.0 |
| Probit (4) | 4.0 |
| Probit (5) | 5.0 |
| p.p. = pontos percentuais. | |
8 Atividade
Leia a seção 11.5 do livro e veja se entendeu toda a interpretação da tabela. Depois disso, responda às perguntas abaixo:
Significância econômica: A diferença na probabilidade de negação entre solicitantes negros e brancos, após o controle por variáveis financeiras, é grande em termos econômicos? Compare com a taxa média de negação na amostra e interprete.
Interpretação causal: Para interpretar o coeficiente de
afamcomo evidência de discriminação racial pelo agente de crédito, quais hipóteses de identificação precisamos assumir? Em particular, o que acontece se os agentes de crédito observam características dos solicitantes que não estão na base de dados e que estão correlacionadas com a raça?Validade interna: Mesmo após incluir todas as variáveis de controle disponíveis, o coeficiente de
afampode ainda estar capturando viés de variável omitida. Que outras características não observadas poderiam estar simultaneamente correlacionadas com a raça do solicitante e com a decisão de negação?Validade externa: Os dados são de Boston em 1990–91. Em que medida os resultados seriam aplicáveis ao mercado imobiliário brasileiro atual? Que diferenças institucionais e contextuais você consideraria relevantes?