Variável dependente binária: modelos não lineares
IBM0288 - 2026.1
Para reflexão
Aula passada: regressão
Nos modelos de MQO que estudamos anteriormente, a função de regressão populacional é dada por:\[E(Y \mid X_1,X_2,\ldots,X_k)\]
Quando \(Y_i \in \{0,1\}\), o valor esperado de \(Y\) é \(p\), ou seja, a probabilidade de \(Y=1\):\[E(Y) = \color{red}{0 \times Pr(Y=0)} + 1 \times Pr(Y=1) = Pr(Y=1)\]
Portanto, para variável binária \(Y\) temos:\[E(Y \mid X_1,X_2,\ldots,X_k)=Pr(Y=1 \mid X_1,X_2,\ldots,X_k)\]
Aula passada: LPM
Um ponto de partida natural é o modelo de regressão linear (Linear Probability Model - LPM) com um único regressor:
\[Y_i = \beta_0 + \beta_1 X_i + u_i\]
o que a reta \(\beta_0 + \beta_1 X\) significa quando \(Y\) é binária?
- \(\Pr(Y=1|X) = \beta_0 + \beta_1 X_i\)
o que \(\beta_1\) significa quando \(Y\) é binária? \(\beta_1 =\frac{\Delta Y}{\Delta X}\)?
- \(\beta_1\) é a mudança nessa probabilidade para uma variação em \(X\)
- os resultados devem ser interpretados como variação em pontos percentuais (p. p.)
o que o valor predito \(\hat{Y}\) significa quando \(Y\) é binária?
- \(\Pr(\hat{Y}=1|X) = \hat{\beta}_0 + \hat{\beta}_1 X_i\)
Aula passada: vantagens e desvantagens
Vantagens:
- Simples de estimar e interpretar
- A inferência é a mesma da regressão múltipla (é necessário usar erros-padrão robustos à heterocedasticidade)
- Mesmas hipóteses em relação a causalidade e efeitos tratamentos
Desvantagens:
O LPM afirma que a mudança na probabilidade prevista é a mesma para todos os valores de \(X\) (linearidade!)
Probabilidades preditas pelo LPM podem ser \(< 0\) ou \(> 1\)!
O que precisamos?
- O problema com o modelo de probabilidade linear é que ele modela a probabilidade de Y = 1 como linear em X:
\[\Pr(Y=1 \mid X) = \beta_0 + \beta_1 X\]
- Em vez disso, queremos:
- \(\Pr(Y=1 \mid X)\) ser crescente em X para \(\beta_1 > 0\), e
- \(0 \leq \Pr(Y=1 \mid X) \leq 1\) para todo X
- Isso requer o uso de uma forma funcional não linear para a probabilidade.
Introdução aos modelos não lineares
A ideia é modelar: \[P(Y_i = 1 \mid X_i) = F(\beta_0 + \beta_1 X_i)\] onde \(F(\cdot)\) é uma função de distribuição acumulada.
Assim garantimos que \(0 \leq P \leq 1\).
Duas escolhas principais:
- \(F = \Phi\) (CDF normal padrão): Probit
- \(F = \Lambda\) (CDF logística): Logit
- \(F = \Phi\) (CDF normal padrão): Probit
Regressão Probit
O modelo probit satisfaz essas condições:
\(\Pr(Y=1 \mid X)\) ser crescente em X para \(\beta_1 > 0\), e
\(0 \leq \Pr(Y=1 \mid X) \leq 1\) para todo X
Probit e a Distribuição Normal
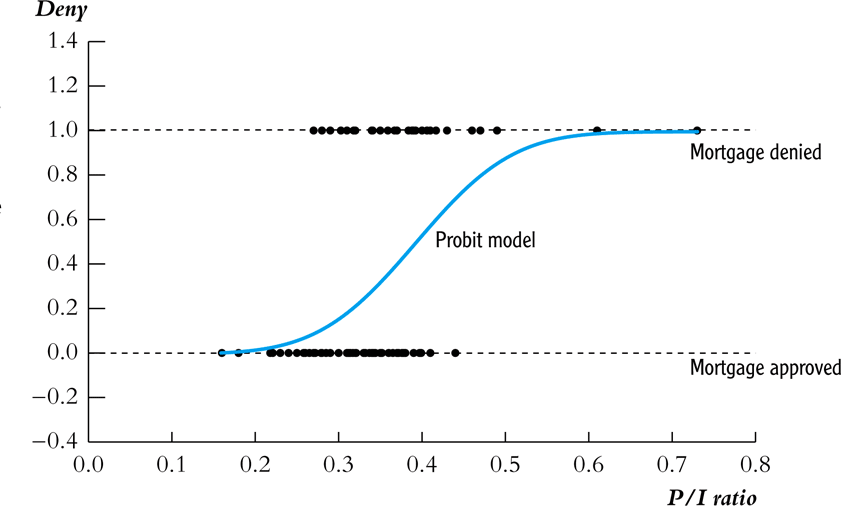
A regressão probit modela a probabilidade de \(Y = 1\) usando a função de distribuição normal padrão acumulada, \(\Phi(z)\), avaliada em \(z = \beta_0 + \beta_1 X\): \[\Pr(Y=1 \mid X) = \Phi(\beta_0 + \beta_1 X)\]
\(z = \beta_0 + \beta_1 X\) é o “valor-z” ou “índice-z” do modelo probit.
Exemplo: Suponha \(\beta_0 = -2\), \(\beta_1 = 3\), \(X = 0{,}4\), portanto
\[\Pr(Y=1 \mid X=0{,}4) = \Phi(-2 + 3 \times 0{,}4) = \Phi(-0{,}8)\]
- \(\Pr(Y=1 \mid X=0{,}4)\) = área sob a curva da densidade normal padrão à esquerda de \(z = -0{,}8\), que é…
Tabela da Normal
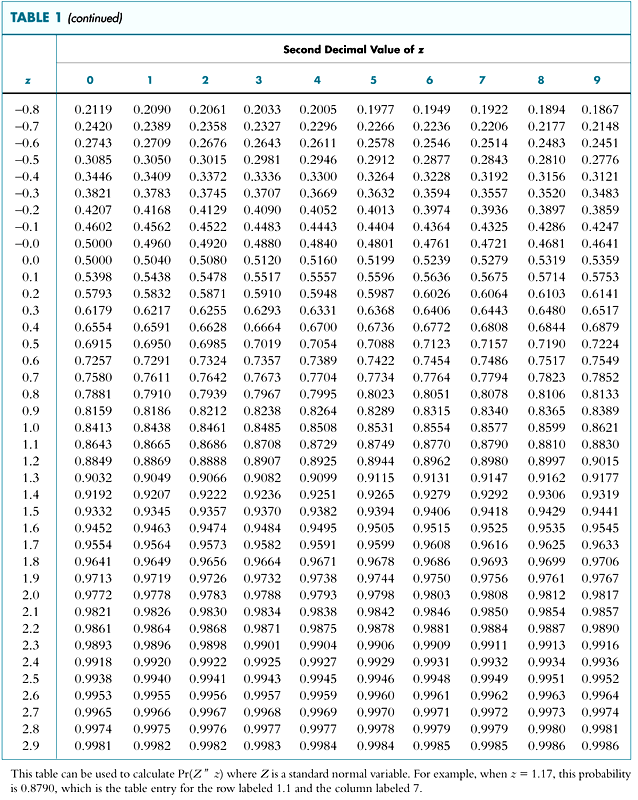 \(\Pr(z \leq -0{,}8) = 0{,}2119\)
\(\Pr(z \leq -0{,}8) = 0{,}2119\)
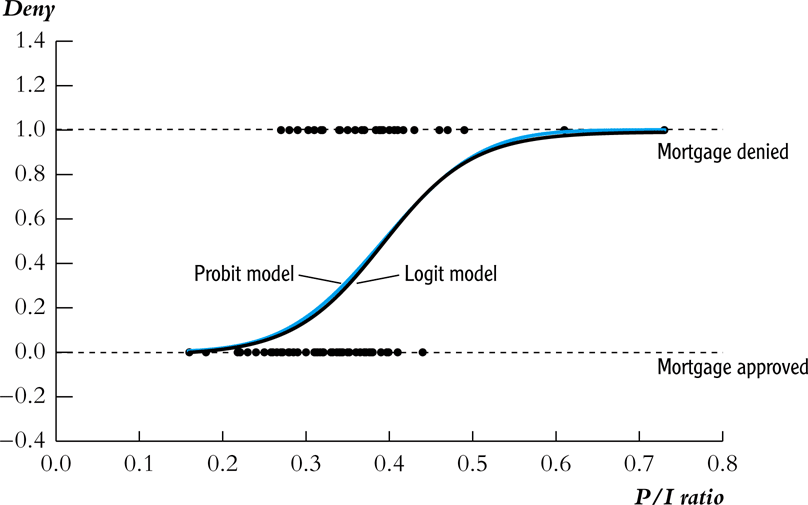
Probit: o caso das hipotecas
\(P(Y_i=1|X_i) = \Phi(\beta_0 + \beta_1 P/I_i)\)
\(\Phi(\cdot)\): CDF normal padrão.
- Para \(P/I = 0,2\) → \(P(deny =1) \approx 2,1\%\)
- Para \(P/I = 0,3\) → \(P(deny =1) \approx 16,1\%\)
- Para \(P/I = 0,4\) → \(P(deny =1) \approx 51,9\%\)
- Para \(P/I = 0,6\) → \(P(deny =1) \approx 98,3\%\)
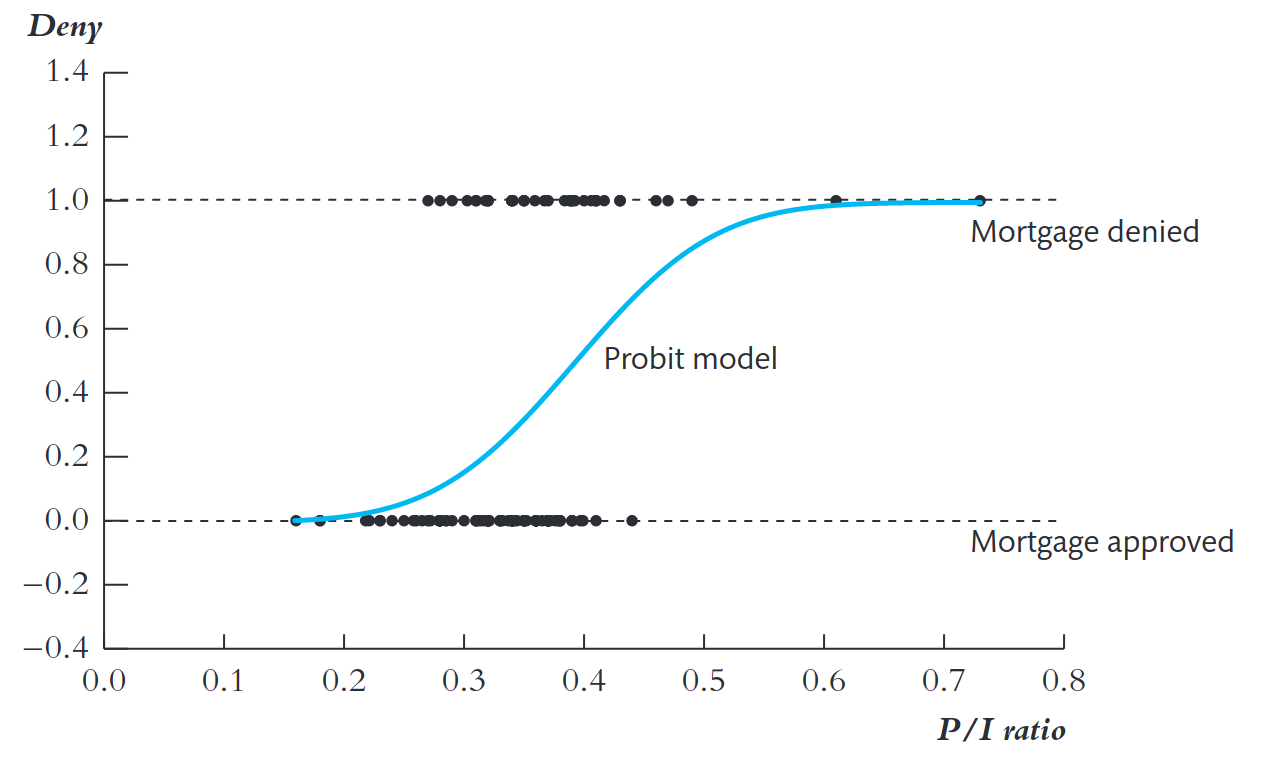
Interpretação: A probabilidade aumenta lentamente para valores baixos de P/I, cresce rapidamente para valores intermediários, e satura em 1 para valores elevados.
Regressão probit com múltiplos regressores
\[\Pr(Y=1 \mid X_1, X_2) = \Phi(\beta_0 + \beta_1 X_1 + \beta_2 X_2)\]
- \(\Phi\) é a função de distribuição normal acumulada.
- \(z = \beta_0 + \beta_1 X_1 + \beta_2 X_2\) é o “valor-z” ou “índice-z” do modelo probit.
- \(\beta_1\) é o efeito sobre o escore-z de uma variação unitária em \(X_1\), mantendo \(X_2\) constante (quando uma interpretação causal é justificada)
Regressão Probit: resumo
Por que usar a função de distribuição normal acumulada?
A “forma em S” nos dá o que queremos:
- \(\Pr(Y=1 \mid X)\) é crescente em X para \(\beta_1 > 0\)
- \(0 \leq \Pr(Y=1 \mid X) \leq 1\) para todo X
Fácil de usar: probabilidades tabeladas e facilmente obtidas no R
Interpretação é relativamente simples:
- \(\beta_0 + \beta_1 X\) = valor-z
- \(\beta_1\) é a variação no valor-z para uma variação unitária em X
Regressão Logit
A regressão logit modela a probabilidade de \(Y = 1\), dado X, como a função de distribuição logística padrão acumulada, \(\Lambda(z)\), avaliada em \(z = \beta_0 + \beta_1 X\):
\[\Pr(Y=1 \mid X) = \Lambda(\beta_0 + \beta_1 X)\]
\[\Lambda(z) = \frac{1}{1 + e^{-z}}\]
Probit vs Logit: valores coeficientes
Como logit e probit utilizam funções de probabilidade diferentes, os coeficientes (\(\beta\)’s) são diferentes nos dois modelos.
Exemplo
\[\Pr(Y=1 \mid X) = \Lambda(\beta_0 + \beta_1 X)\]
- Exemplo: \(\beta_0 = -3\), \(\beta_1 = 2\), \(X = 0{,}4\),
- portanto \(\beta_0 + \beta_1 X = -3 + 2 \times 0{,}4 = -2{,}2\) logo
- \(\Pr(Y=1 \mid X=0{,}4) = 1/(1 + e^{-(-2{,}2)}) = 0{,}0998\)
Probit vs Logit
Por que usar logit se temos probit?
- A razão principal é histórica: o logit é computacionalmente mais rápido e simples, mas isso não importa mais hoje em dia
Na prática, logit e probit são muito semelhantes!
Como interpretar os coeficientes?
O coeficiente \(\beta_1\) representa a diferença no valor de \(z\) associada ao aumento de \(X_1\) em uma unidade, mantendo as demais variáveis constantes \(X_2, \ldots, X_k\).
Como o modelo é não linear, o impacto sobre a probabilidade prevista não é constante.
Como calcular o efeito marginal aproximado da mudança de um regressor?
- Calcular a probabilidade predita para os valores iniciais;
- Calcular a probabilidade predita para o novo valor do regressor;
- Calcular a diferença entre as duas probabilidades preditas.
A interpretação depende do ponto da curva: o mesmo incremento em \(X_1\) pode gerar efeitos diferentes conforme o valor inicial.
Estimação por Máxima Verossimilhança: intuição
Estimação por Máxima Verossimilhança: formalização
Para variáveis binárias, a verossimilhança é:\[L(\beta) = \prod_{i=1}^{n} [P_i]^{Y_i} [1-P_i]^{1-Y_i}\] com: \(P_i = F(\beta_0 + \beta_1 X_i)\)
Maximizamos o logaritmo:\[\ln L(\beta) = \sum_i \left[ Y_i \ln P_i + (1-Y_i)\ln(1-P_i) \right]\]
Estimação feita numericamente (ex.: algoritmo Newton-Raphson).
Propriedades do estimador MLE
Consistente: converge para o valor verdadeiro conforme \(n \to \infty\).
Assintoticamente normal:\[ \sqrt{n}(\hat{\beta} - \beta_0) \to N(0, \sigma) \]
Eficiente: menor variância assintótica entre estimadores consistentes.
Erros-padrão e inferência
Erros-padrão baseados na matriz de informação de Fisher:\(\hat{V}(\hat{\beta}) = (H^{-1})\) onde \(H\) é a matriz Hessiana da log-verossimilhança.
Intervalos de confiança:\(\hat{\beta}_j \pm 1.96 \cdot SE(\hat{\beta}_j)\)
- Testes:
- \(z\)-teste individual.
- Teste de razão de verossimilhança.
Medidas de ajuste
O \(R^2\) tradicional não é aplicável.
Usamos o pseudo-R² de McFadden:\[R^2_{MF} = 1 - \frac{\ln L_{\text{modelo}}}{\ln L_{\text{nulo}}}\]
Fração corretamente prevista
Existe discriminação racial no mercado de crédito imobiliário?
Ver resultados nas Tabelas do livro.
Angrist & Pischke: visão prática sobre Y binário
- LPM
- Útil e suficiente para inferência causal;
- Fácil de estimar, interpretar e combinar com VI, efeitos fixos, dif-in-dif.
- Use erros-padrão robustos;
- Previsões fora de \(0,1\) não invalidam a consistência do efeito médio quando há exogeneidade.
- Útil e suficiente para inferência causal;
- Logit/Probit
- Impõem probabilidades entre \(0,1\), mas efeitos marginais geralmente próximos aos do LPM.
- Escolha da CDF muitas vezes é secundária: foco tem que ser no desenho de pesquisa e na identificação.
- Impõem probabilidades entre \(0,1\), mas efeitos marginais geralmente próximos aos do LPM.
Guia Prático
Guia Prático
O cerne deve ser a identificação causal. Forma funcional não salva identificação ruim!
Prática recomendada: reporte LPM com errros-padrão robustos e, se quiser, logit/probit para mostrar robustez dos resultados.
Declínio de modelos probit desde Angrist & Pischke
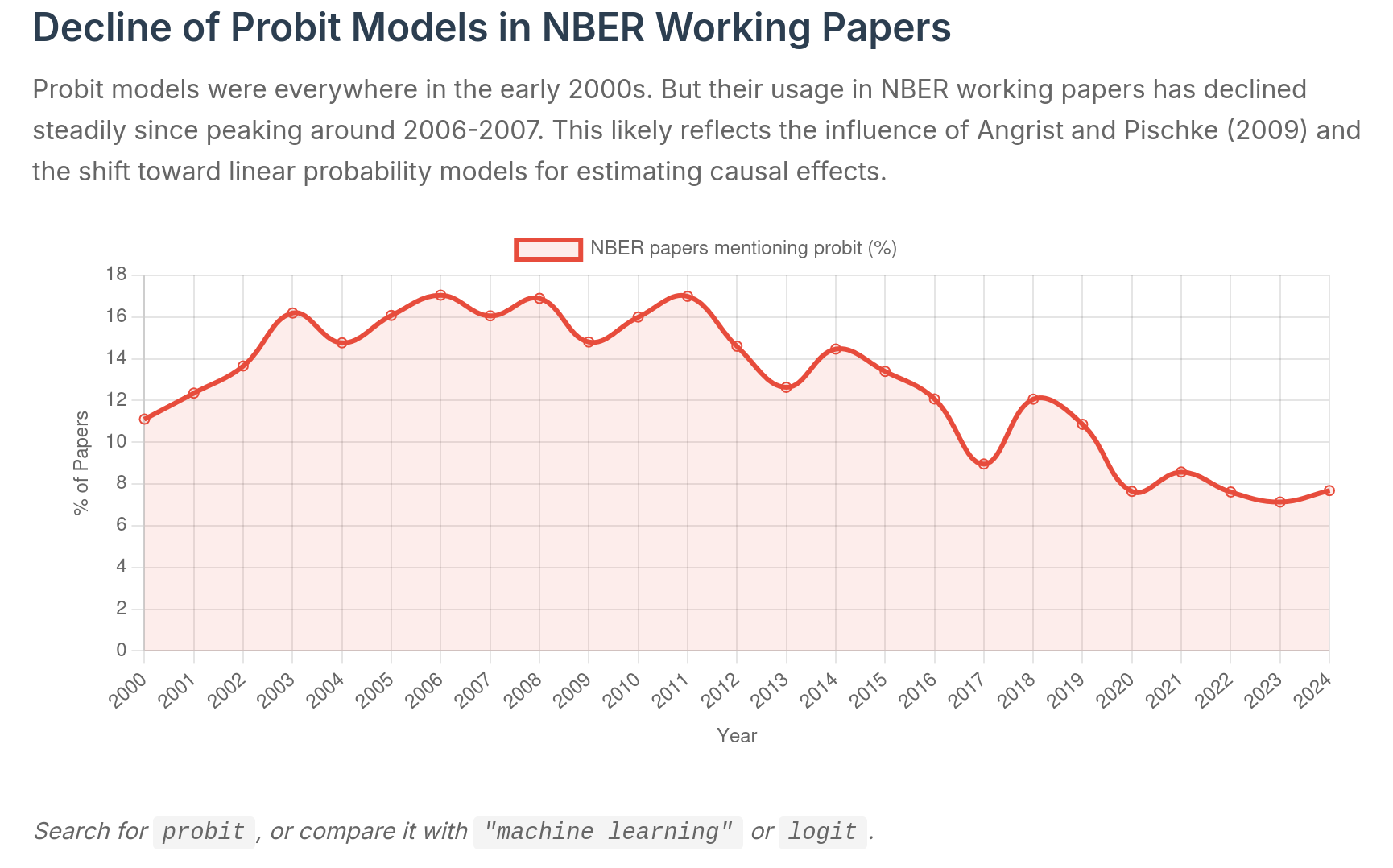
Fonte: Economics Literature Search

O uso de celulares e computadores durante as aulas expositivas não é permitido!