Variável dependente binária: modelo de probabilidade linear
IBM0288 - 2026.1
Para reflexão
O caso das hipotecas
- Contexto: o agente bancário avalia se o solicitante conseguirá pagar o empréstimo.
- Indicador-chave: a razão P/I = pagamento mensal / renda mensal.
- Variável dependente:
deny = 1se a solicitação foi negada,0se aprovada.
- Padrão observado:
- Quando P/I < 0,3, quase ninguém é negado.
- Quando P/I > 0,4, a maioria é negada.
- Quando P/I < 0,3, quase ninguém é negado.
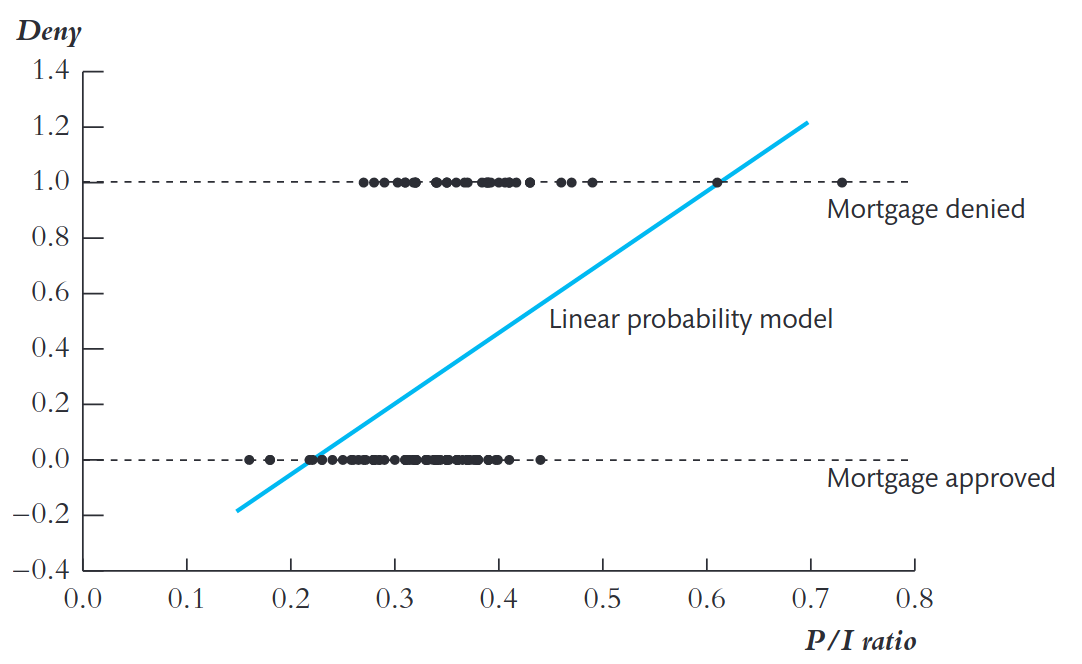
Obs: Gráfico com apenas 127 observações para facilitar visualização
Resultados
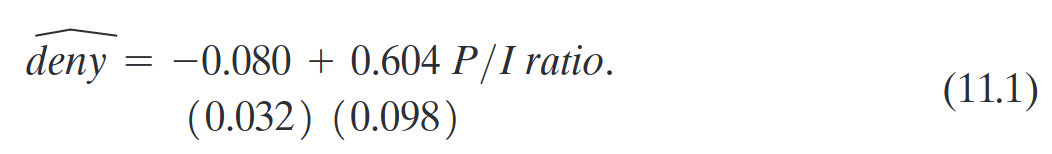
Valor predito para razão P/I = 0,3:
\[\hat{Y} = -0{,}080 + 0{,}604 \times 0{,}3 = 0{,}101\]
Calculando efeitos: aumento da razão P/I de 0,3 para 0,4:
\[\Delta\hat{Y} = 0{,}604 \times (0{,}4 - 0{,}3) = 0{,}061\]
O efeito de aumentar a razão P/I de 0,3 para 0,4 é elevar a probabilidade de negação em 0,061 (ou seja, 6,1 pontos percentuais).
Evidências de discriminação?
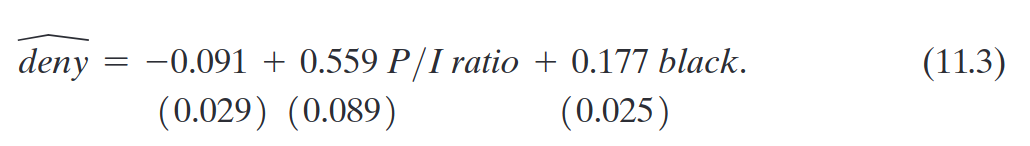
Probabilidade predita de negação para candidato negro com P/I = 0,3:\[Pr(deny =1)=-0,91+0,559\times 3 + 0,177 \times 1 = 0,254\]
Probabilidade predita de negação para candidato branco com P/I = 0,3: \[Pr(deny =1)=-0,91+0,559\times 3 = 0,077\]
Diferença = 0,177 = 17,7 pontos percentuais
O coeficiente em
negroé significativo ao nível de 5%
Qual sua conclusão? Existe evidência de discriminação racial nesse mercado?
